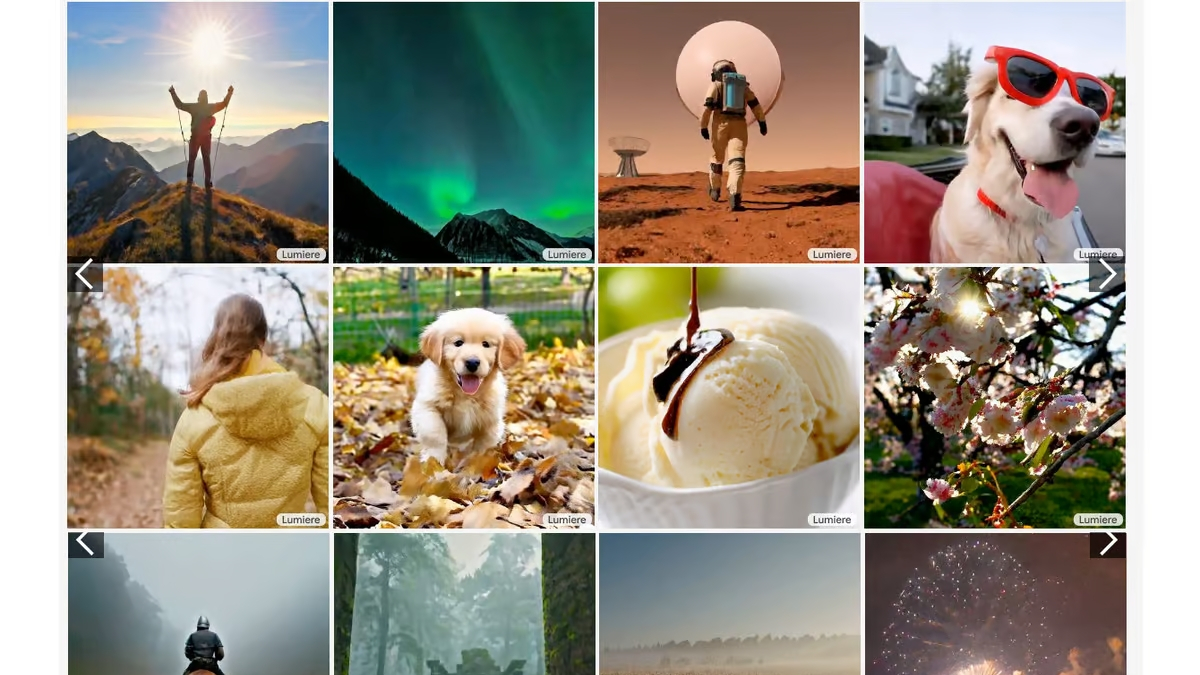
Google has now announced the introduction of Lumiere, an AI video generator that creates videos from text prompts.
Lumiere is probably one of the newest and most advanced AI video generators in existence today. It’s also making inroads in an area of AI rendering that until recently hasn’t been developed nearly as robustly as AI text generation or image rendering.
Video until now has been one of the last bastions of digital visual creativity that AI wasn’t quite able to penetrate, but it was just a matter of time.
Google claims that the name of its AI is a homage to the Lumiere brothers, who created the first cinema way back in 1895.
Motion pictures were the most advanced, utterly new visual technology of the late 19th century, and Lumiere the AI’s video creations can be claimed to hold the same place of honor in the early 21st.
Critics however might point out that at least the nascent motion pictures of the 1890s depended on persistent human creativity.
Today, Lumiere the AI arguably takes from it after the AI’s initial development and refinement. That however is something of a separate issue with this technology.
For now, in practical terms, Lumiere is visually impressive. In a demo released by Google to Github, the software focused largely on rendering animals.
Just like image generators such as Midjourney, the model creates a scene by using text prompts. With this fairly simple control process, users can pretty much dream up anything they like and as long as they word their prompts carefully, Lumiere will generate it as an effective video clip.
One other ability of Lumiere makes the above even more interesting or at least easier: The AI can also generate clips from image prompts. Google itself demonstrated this through several examples of famous photos.
One of these was the iconic historical photo “Raising the Flag” by Joe Rosenthal, which shows American marines raising a US flag on top of the ruined island of Iwo Jima during WWII.
By then adding the prompt “Soldiers raising the United States flag on a windy day”, Google turned the static image into a video of the soldiers struggling with the flag pole as gusts of wind violently move the flag itself.
Also, unsurprisingly, Lumiere can be used to modify existing videos in different ways. The AI comes with a “Video Stylization” option that lets you upload a real video and then have the generative AI change elements of it in all sorts of mundane or very unusual ways.
To give an example of the latter, a video of someone running could be changed to make the person look like they’re a toy made of colored bricks.
Another tool in Lumiere is called “Cinemagraphs”. With this, a section of an image can be animated while the rest is left static. Then there’s “Video Inpainting”, which lets a user mask part of an image and modify that section however they like.
Overall, Lumiere is impressive despite some obvious AI artifacts in some of the videos it creates. Video production professionals might either rejoice at the new tools it could offer them or worry about what it will mean for their career prospects.
Alphabet/Google claims that Lumiere is powered by “Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model.”
If that sounds just a bit confusing, bear in mind that it’s in contrast to older video rendering models that were only able to “synthesize distant keyframes followed by temporal super-resolution — an approach that inherently makes global temporal consistency difficult to achieve.”
Hopefully, that clarifies things.
Basically, though, Lumiere processes video elements all at once while many older models did the same in pieces incrementally.
Lumiere is in any case much more functional than many previous efforts at AI video rendering that we’ve seen so far. In fact, it’s the first publicly released tool so far that takes a deep stab at doing to video what AI image and text tools did to those mediums.
As is common among these complex LLM (Large Language Model) AI tools, Lumiere was trained using colossal amounts of existing visual data previously generated by human creators.
Also typically of the companies behind AI LLM systems, Google is being vague about what their own training set for the AI was.
The company did state that “We train our T2V [text to video] model on a dataset containing 30M videos along with their text caption. [sic] The videos are 80 frames long at 16 fps (5 seconds). The base model is trained at 128×128.”
Google does own YouTube so that right there is at least one obvious possible source of absolutely huge loads of video clips that they can legally access for this new AI system.
Highly Recommended
8 Tools for Photographers
Check out these 8 essential tools to help you succeed as a professional photographer.
Includes limited-time discounts.
Learn more here





